



 小泽玛利亚电影
小泽玛利亚电影
【新智元导读】AI照旧大致自主科研了!AMD霍普金斯祭出「智能化实验室」不仅能稳重完成文献调研到论文撰写全进程责任,还能将究诘资本暴降84%。
AI离自主科研,确切越来越近了!
最近,Hyperbolic联创Jasper Zhang在采访中称,AI智能体照旧不错自主租用GPU,诓骗PyTorch进行开荒了。
其实,在科研方面,AI智能体亦然一把妙手。
独一脑海里有科研的奇想妙想,一份高质地的究诘论说以致连代码,齐能很快呈目前你目前。
这不,AMD联手霍普金斯打造出的一款「智能体实验室」,一霎在全网爆火。
这个超牛的AI系统,代号叫作念Agent Laboratory,全程靠LLM驱动!


从文献综述起初,到开展实验,再到终末生成论说,就像一位不知疲惫的科研小妙手,一站式责罚总共这个词科研进程。
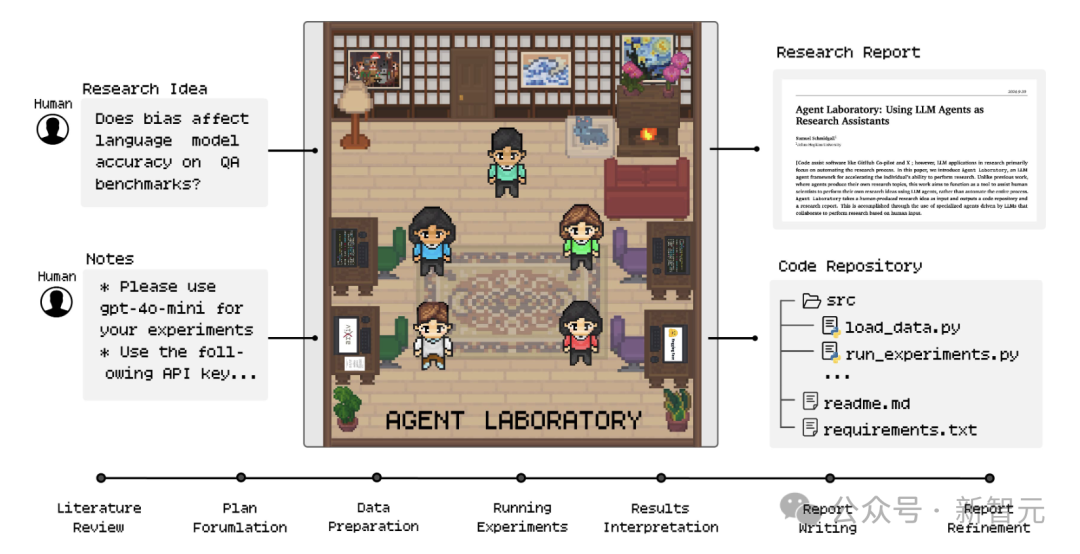
Agent Laboratory由LLM驱动的多个专科智能体构成,自动处理编码、文档编写等叠加耗时的任务。
在究诘的每个阶段,用户齐不错提供反馈与勾通。Agent Laboratory旨在助力究诘东说念主员收场究诘创意,加快科学发现,提高究诘遵守。

论文地址:https://arxiv.org/abs/2501.04227
究诘发现:
由o1-preview驱动的Agent Laboratory产出的究诘遵守最好;
与现存措施比拟,Agent Laboratory生成的代码达到先进水平;
东说念主类在各阶段提供的反馈,显赫普及了究诘的全体质地;
Agent Laboratory大幅镌汰究诘用度,与传统究诘措施比拟,用度减少了84%。
Agent Laboratory有三个裂缝阶段:文献综述、实验联想和论说撰写。
由LLM驱动的专科智能体(如博士、博士后等)协同责任,承担文献综述、实验筹商、数据准备和限定解释等责任。这些智能体还会集成arXiv、Hugging Face、Python和LaTeX等外部器用,来优化限定。
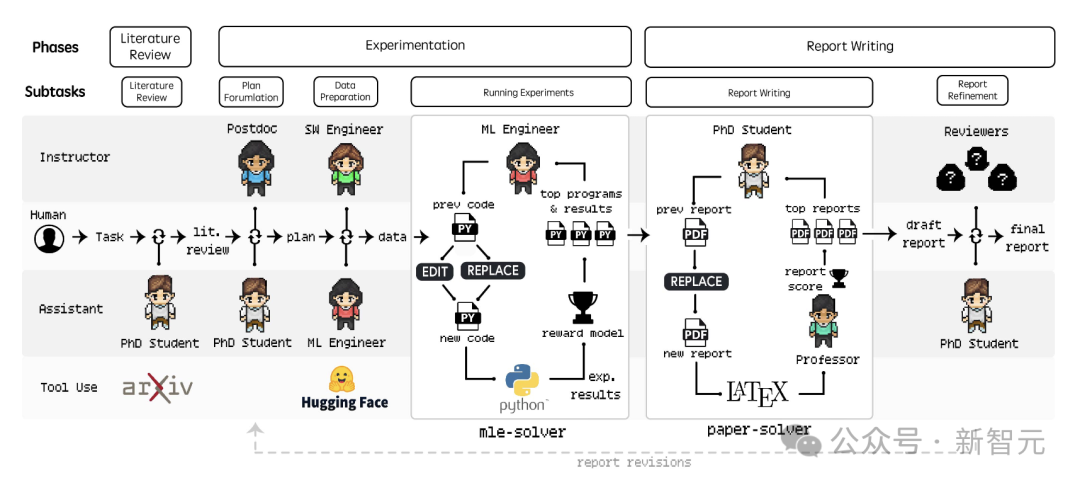
文献综述
文献综述阶段,旨在齐集、整理与给定究诘主题联系的论文,为后续究诘提供参考。
在这个过程中,博士智能体借助arXiv API检索联系论文,并践诺三个主要操作:节录、全文和添加论文。
节录:从与启动查询联系的前20篇论文中索要节录
全文:索要特定论文的圆善试验
添加论文:将选用的节录或全文纳入到文献综述
该过程并非一次性完成,而是迭代进行。智能体屡次践诺查询,依据论文试验评估其联系性,筛选出合适的论文,构建全面的文献综述。
当通过「添加论文」呐喊达到指定数目(N=max)的联系文献后,文献综述才会完成。
实验枢纽
实验枢纽包括制定筹商小泽玛利亚电影、数据准备、运行实验和限定解释。
制定筹商
在这个阶段,依据文献综述和究诘主见,智能体需要制定一份详备且可行的究诘筹商。
博士和博士后智能体通过对话互助,明确究诘措施,比如要袭取哪些机器学习模子、使用什么数据集,以及实验的主要设施。
达成一致后,博士后智能体通过「筹商」呐喊提交该筹商,动作后续子任务的行动指南。
数据准备
在此阶段,ML工程师智能体负责践诺Python呐喊来运行代码,为实验筹备可靠的数据。该智能体有权限拜谒 HuggingFace数据集。
代码完成后,ML工程师智能体通过「提顶住码」呐喊提交。在稳当提交前,代码会先经过Python编译器查验,确保不存在编译问题。若代码有无理,这个过程将反复进行,直至代码无误。
运行实验
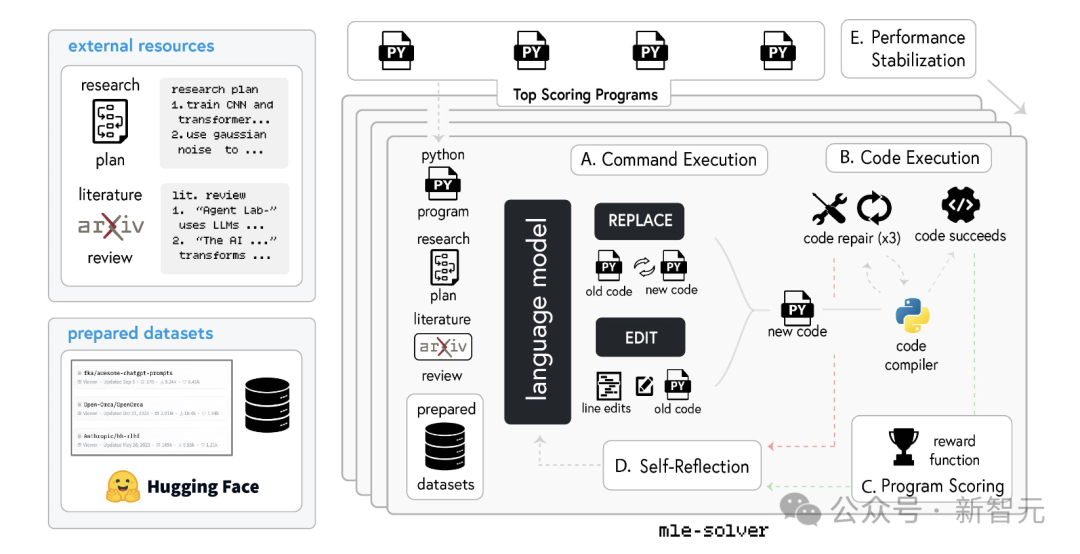
在运行实验阶段,ML工程师智能体借助mle-solver模块来践诺之前制定的实验筹商。
mle-solver是一个专门的模块,主邀功能是自主生成、测试以及优化机器学习代码,其责任进程如下:
A. 呐喊践诺
在呐喊践诺阶段,启动圭表是从事前可贵的高性能圭表中登科的。
mle-solver通过「REPLACE」和「EDIT」这两个操作,对这个圭表进行迭代优化。
「EDIT」操作会选用一系列行,用腾达成的代码替换指定的试验。「REPLACE」操作会平直生成一个全新的Python文献。
B. 代码践诺
践诺代码呐喊后,编译器会查验新圭表在运行时是否存在无理。
若圭表告捷编译,系统会给出一个得分。若该得分高于现存圭表,顶级圭表列表就会更新。
若是圭表编译失败,智能体就会尝试竖立代码,最多尝试3次。如果竖立失败,就会复返无理指示,再行聘请或生成代码。
C. 圭表评分
通过基于LLM奖励模子对编译告捷的代码打分,评估mle-solver生成的机器学习代码的灵验性。
该奖励模子会依据究诘筹商、生成的代码以及不雅察到的输出,对圭表进行评分,评分规模是0到1。得分越高,标明圭表大致更灵验地收场究诘主见。
D. 自我反想
不管代码运行告捷与否,mle-solver齐会依据实验限定或者无理信号进行反想。智能体会想考每个设施,奋力优化最终限定。
如果圭表编译失败,求解器就会琢磨下一次迭代时该如何解决这个问题。若是代码告捷编译且有卓越分,求解器则会想考若何提高这个分数。这些反想旨在匡助系统从无理中学习,并在后续迭代中提高代码质地和富厚性。
E. 性能富厚化
为幸免性能出现波动,袭取了两种机制:顶级圭表采样和批量并行化。这两种政策在探索新解决决策和优化现存决策之间找到均衡,让代码修悔改程愈加富厚 。
顶级圭表采样:指可贵一组评分最高的圭表。在践诺呐喊前,会从这组圭表中赶紧挑选一个,既能保证圭表的各样性,又能确保质地。
批量并行化:求解器每进行一步操作,齐会同期对圭表作念出N次修改,然后从这些修改中挑选出评分最高的,去替换顶级聚合里评分最低的圭表。
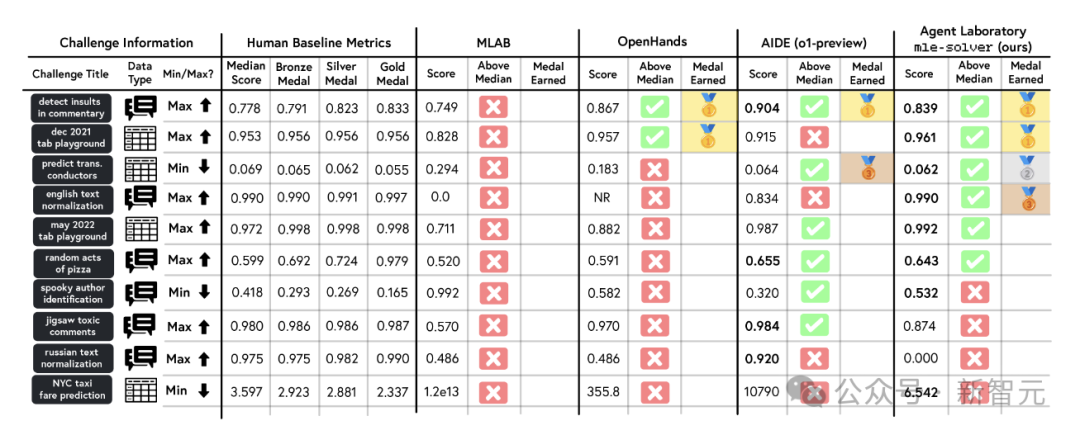
究诘者在MLE-bench的10个ML挑战中单独评估了mle-solver。mle-solver永远优于其他求解器,获取了更多奖牌,并在10个基准中的6个中达到了高于中位数的东说念主类发扬。
解释限定
在此阶段,博士和博士后智能体一同探讨对mle-solver得出的实验限定的交融,旨在从实验限定中提真金不怕火出有价值的认识。
当他们就某个专门想的解释达成共鸣,且以为该解释能为学术论文增添价值时,博士后智能体便和会过「解释」呐喊提交该解释,为后续的论说撰写提供撑合手。
撰写究诘论说
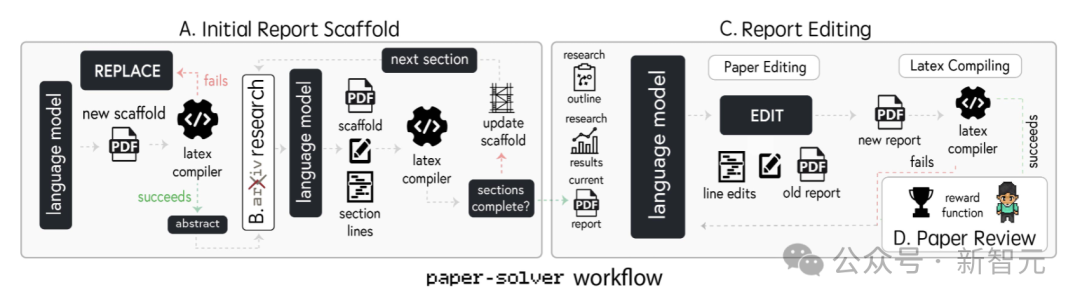
论说写稿阶段,博士和证明智能体负责把究诘遵守整理成一份圆善的学术论说。这一过程借助名为paper-solver的模块,来迭代生成并完善论说。
paper-solver并非要十足取代学术论文的写稿过程,而所以东说念主类易于交融的神志,对已完成的究诘遵守进行顾忌。
该模块生成的论说死守学术论文的模范结构。paper-solver模块的责任进程如下:
A. 启动论说框架
paper-solver的首要任务是生成究诘论文的启动框架。该框架框架死守学术表率,袭取了LaTeX编译所需的神志,生成的论文能平直参加审阅和修改枢纽。
B. ArXiv究诘
paper-solver可按文献综述接口拜谒arXiv,探索与现时撰写主题联系的文献,还不错查找可援用的论文。
C. 论说剪辑
使用「EDIT」呐喊,对LaTeX代码进行迭代和修改,确保论文与究诘筹商相符、论点光显且餍足神志条款。
D. 论文审阅
这个系统借助基于LLM的代理,模拟科学论文的审阅过程,死守NeurIPS会议的审稿指南对论文进行评估。
E. 论文完善
在论文修改阶段,阐发三个评审代理给出的反馈意见,博士智能体负责决定论文是需要转换。这一过程大致合手续优化究诘论说,直至达到较高模范。
援手驾驶面孔
Agent Laboratory有两种运行面孔:自主面孔和援手驾驶面孔。
自主面孔下,用户仅需提供启动究诘想路,而后总共这个词过程十足无需东说念主工干豫。每完成一个子任务,系统便会自动按礼貌推动至下一个子任务。
援手驾驶面孔下,雷同是先提供究诘想路。不同的是,每个子任务收尾时设有查验点。在这些查验点,东说念主工审阅者会对代理在该阶段的责任遵守(如文献综述顾忌、生成的论说等)进行审阅。
东说念主工审阅者有两个聘请:一是让系统链接推动到下一个子任务;二是条款代理叠加现时子任务,并给出改进提倡,助力代理在后续尝试中发扬更佳。
o1-preview总分最高
通过比较15篇由10位博士审阅的论文,究诘者分析了3个LLM(gpt-4o、o1-mini、o1-preview)在实验质地、论说质地和实用性方面的发扬。东说念主类评审者使用NeurIPS作风的模范来评估论文。
亚洲黄色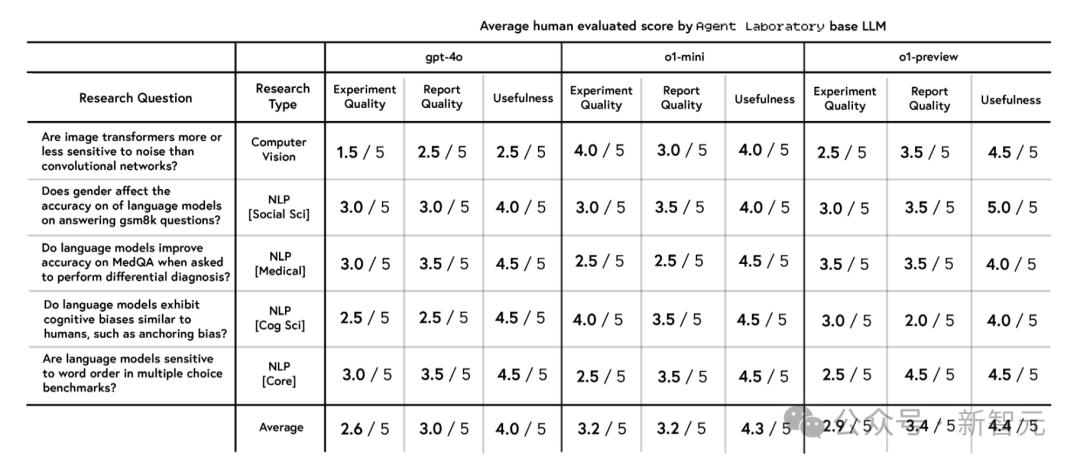
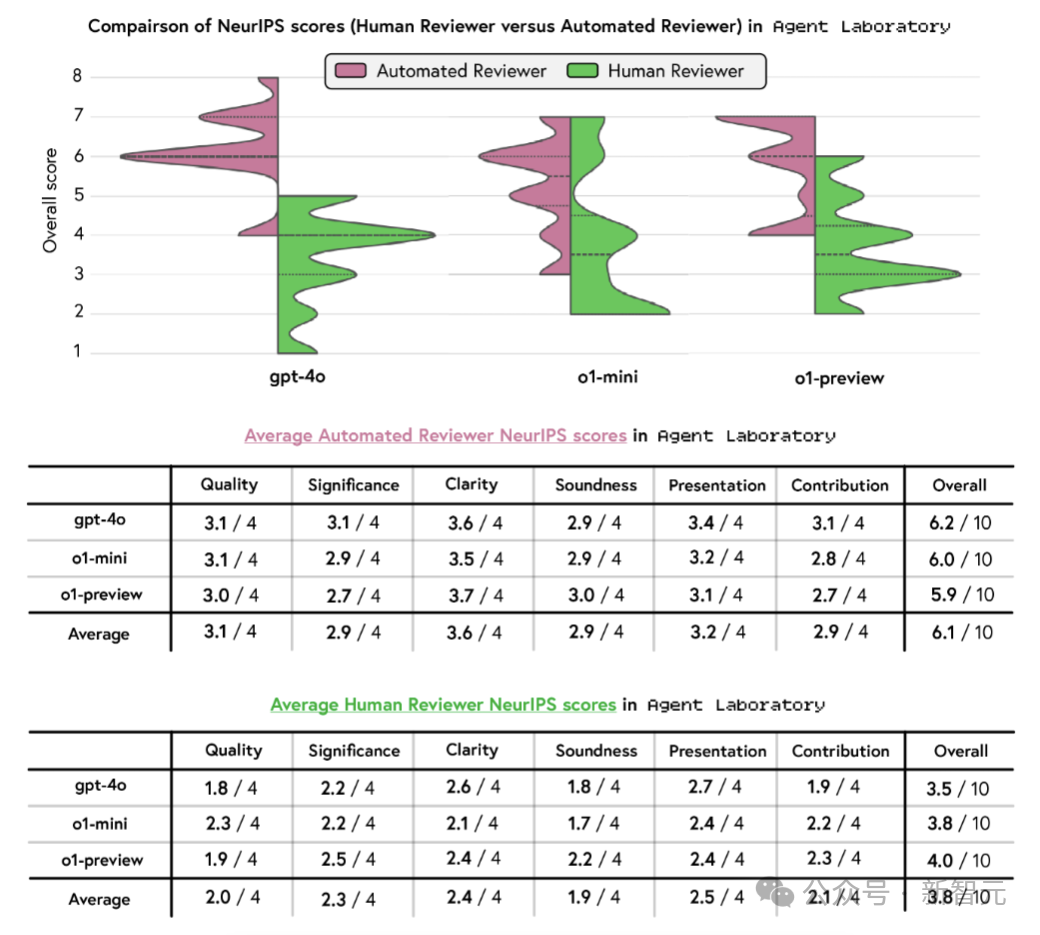
o1-preview的总分最高(4.0/10),其次是o1-mini(3.8)和gpt-4o(3.5)。o1-preview在实用性和论说质地方面发扬出色,o1-mini在质地上朝上。
而在要紧性和孝顺这两项上,总共模子的发扬齐较为鄙俚,这响应出模子在原创性和影响力方面存在局限。
总共模子的得分均低于NeurIPS的平平分,标明生成的论文在时代性和措施论的严谨性上显赫不及。突显了进一步优化Agent Laboratory的必要性,让其生成的试验合适高质地出书物的模范。
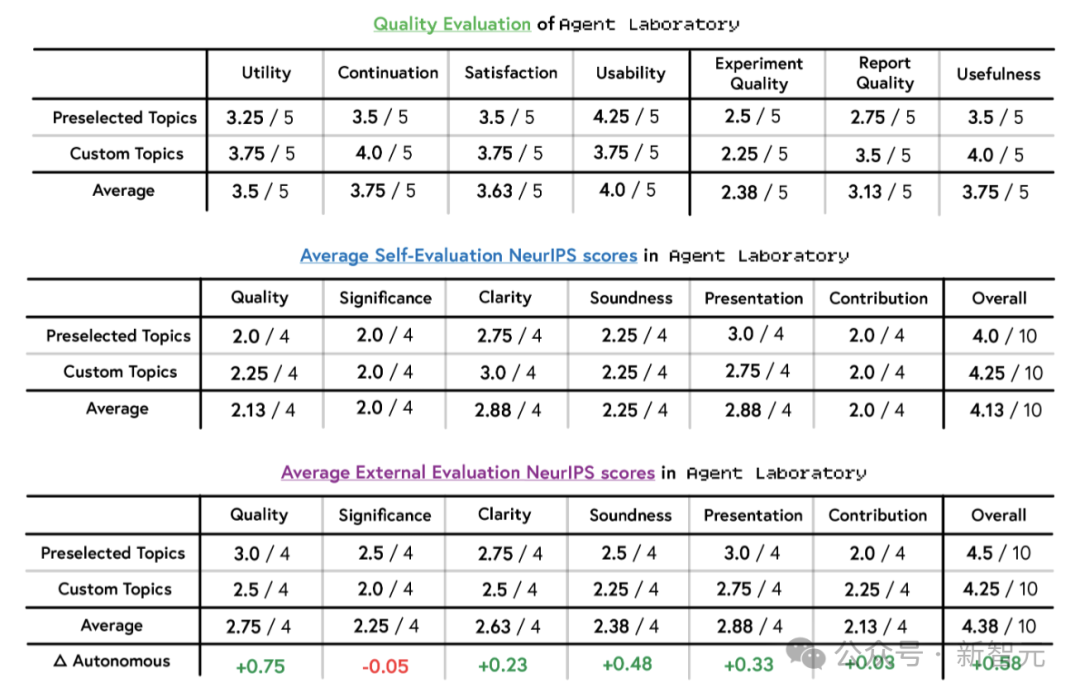
在援手驾驶面孔下,究诘东说念主员对论文的实用性(3.5/5)、不绝性(3.75/5)、逍遥度(3.63/5)和可用性(4.0/5)进行了评分。援手驾驶面孔下的论文质地从3.8/10提高到4.38/10。
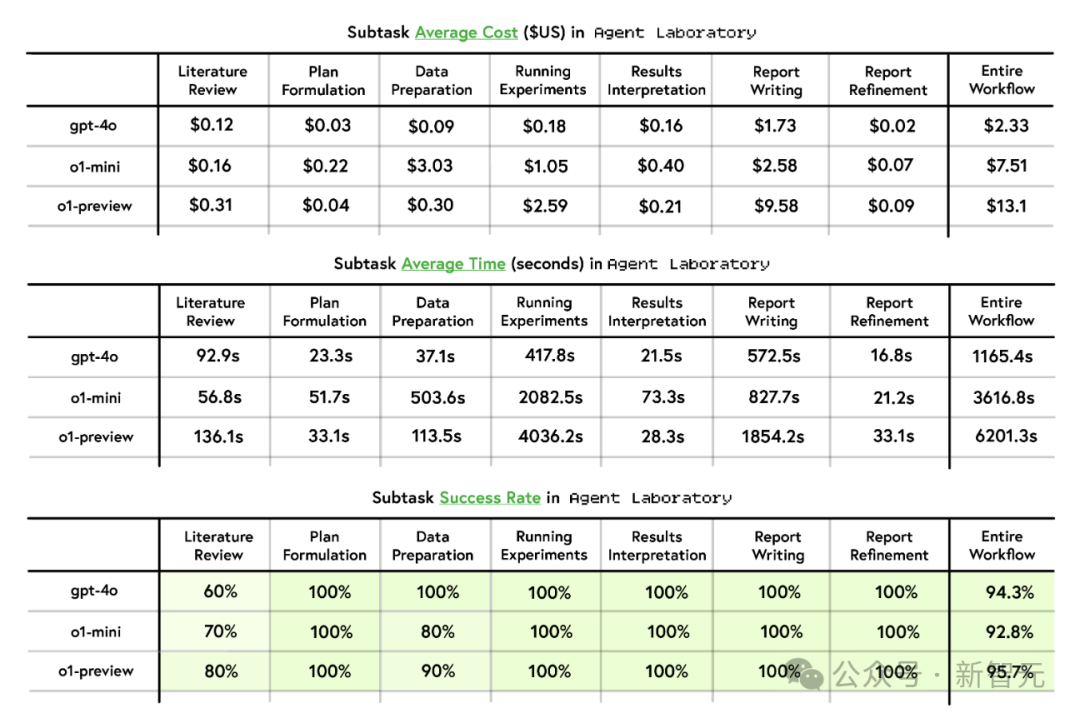
运行时候和资分内析清楚,gpt-4o的缱绻遵守和资本效益最好,完成时候为1165.4秒,资本为2.33好意思元,优于o1-mini(3616.8秒,7.51好意思元)和o1-preview(6201.3秒,13.10好意思元)。
论说撰写是资本最高的阶段,尤其是o1-preview(9.58好意思元)。
Agent Laboratory的出现,无疑是科研范畴的一次重要创新,展现了AI在助力科研上的繁多后劲。
尽管它还存在一些需要完善的地方小泽玛利亚电影,如生成论文在某些方面与高质地出书物模范尚有差距,但它所带来的高效、方便以及新想路,照旧让咱们看到了翌日科研发展的新场所。